Soo Machine & Auto: Unearthing a Lost Legacy, Amplified by AI
Kyle Niewiada
September 09, 2024 |
41 Minute Read
Updated on May 21, 2025

Late Nights and Legacy: A Digital Excavation into Soo Machine & Auto
“Soo Machine & Auto Co.” It was a name lost to time, a puzzle with missing pieces. Until a few months ago, I’d never even heard of this car dealership. But when I learned my great-grandfather was once their customer, a spark ignited. A research volunteer provided the initial clues, setting the stage for my own late-night quest. In the quiet hours after my kids were tucked into bed, with an AI as my guide, I embarked on a journey to piece together the rest of the story.
This captivating project has led me down an intriguing path, merging historical research with the power of technology and a sprinkle of late-night coding adventures. It’s a tale of web scraping, AI-powered analysis, and the thrill of discovery—all in pursuit of breathing life back into this forgotten chapter of automotive history. Join me on this expedition as we blend human expertise and artificial intelligence to uncover the secrets of Soo Machine & Auto Co.
My story is fun, but if you’d like to skip it, you’ll find all my discoveries about Soo Machine & Auto Co. in the history section below.
Post Changelog
- 2024-09-09: Extended LaSalle years based on a newly found advertisement.
- 2024-09-10: Update Robert Morrison’s year of birth and include new adoptive theory.
Table of Contents
-
Late Nights and Legacy: A Digital Excavation into Soo Machine & Auto
- The Spark: A Curated Packet of Information
- The Hunt: Identifying Relevant Articles
- The Solution: Automation to the Rescue
- The Challenges: Troubleshooting and Optimization
- The Transformation: Preparing Data for AI Analysis
- The Tumble: NotebookLM and its Limits
- The Reduction: Crafting a Dataset for AI Analysis
- The Payoff: Unlocking Lost Secrets with NotebookLM
- Soo Machine & Auto Co.: A Brief History
- Information Bounties
- Reflections: The Joy of Discovery and the Power of Automation
The Spark: A Curated Packet of Information
My journey began with a spark of curiosity. This summer, I discovered from some documents that my great-grandfather purchased a vehicle from a dealership called “Soo Machine & Auto Co.” decades before I was born. Intrigued by this connection to a car in the family, I set out to learn more about the dealership. But when I searched online, I was only met with a single page of results from Google. 😔

My initial online searches had yielded frustratingly little. But then, a glimmer of hope emerged from an unexpected source. I learned about historical societies. These dedicated organizations chronicle and archive the stories of their communities. It was a resource I’d completely overlooked! I discovered that the city where Soo Machine & Auto once stood had its own historical society, a beacon in my quest for answers.
I reached out to the Chippewa County Historical Society and was delighted to discover that they did indeed know of Soo Machine & Auto. We worked out a deal where I arranged for some photos from their archive and for them to search through their records for information about Soo Machine & Auto Co. We agreed on the scope, and I formalized my request. Sandy, one of their volunteers, embarked on a 4-hour research mission on the dealership and its key individuals. She was extremely helpful and returned back with a packet of excerpts from historical documents related to the Soo Machine & Auto and its owners. My first taste of information was a tantalizing glimpse into the dealership’s past.
The excerpts, which spanned from 1911 to 1974, illustrated the company’s growth and development. From its early days as a Rambler dealership to a multi-line dealership of Buick, Cadillac, Pontiac, and GMC Trucks. The documents highlighted the significant role that Roy D. Hollingsworth played in the company’s history, including his ownership, community involvement, and military service. Furthermore, the inclusion of personal letters from Governor Chase S. Osborn to Hollingsworth emphasized his standing in the community.
Overall, these snippets painted a vivid picture of a successful local business and its dedicated owners, deeply intertwined with the Sault Ste. Marie community. But I still had unanswered questions. I wanted to dig deeper.
The Hunt: Identifying Relevant Articles
A key learning from the information packet was noticing the overwhelming appearance of articles from a specific local newspaper, The Evening News in Sault Ste. Marie. Looking to continue my quest, I turned to their website before stumbling upon their digital archive. I was fortunate to find that the newspaper had already digitized much of their collection and partnered with a company called Newsbank to provide access to its archive of historical newspapers.
The Evening News digital archive: https://sooeveningnews.newsbank.com
The archive held thousands of newspapers spanning decades. Buried somewhere in the articles was the evolution of the Soo Machine & Auto Co. I was eager to extract valuable insights from this treasure trove, but the sheer volume of data presented a formidable challenge.
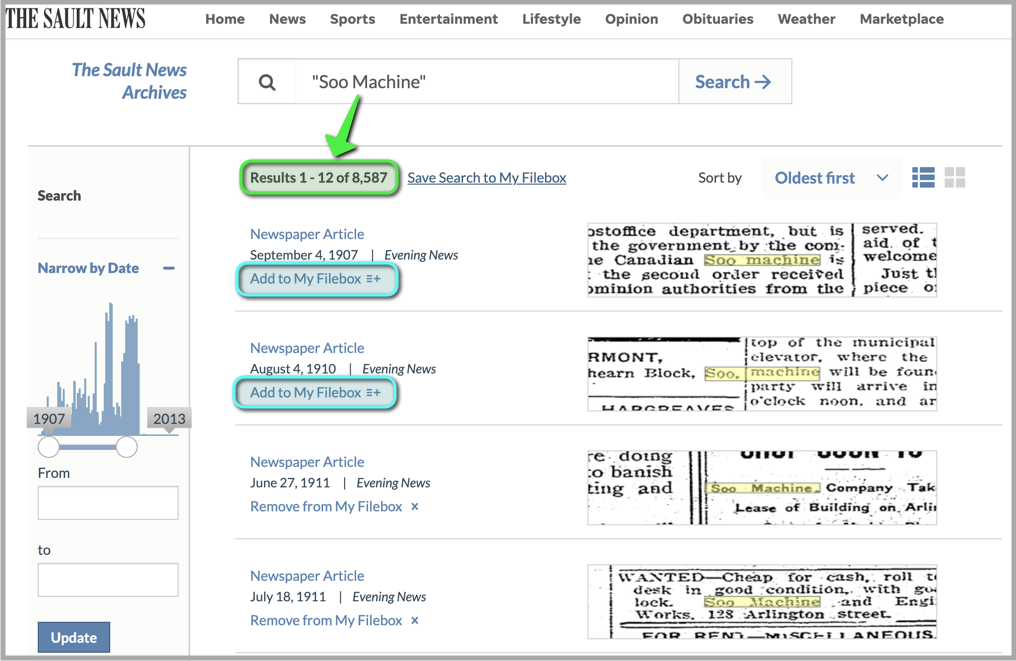
My first search in the archive, “Soo Machine”, returned over 8,000 results! This was leagues ahead of anything I had uncovered through Google. If I searched for “Roy Hollingsworth”, it returned another 1,000 results! I was overwhelmed by the sheer volume of information. But I was determined to uncover the dealership’s story, piece by piece. I had to find a way to navigate this vast archive and extract the information I needed.
My first task was to pinpoint articles of interest within the massive repository. I meticulously crafted keyword searches, focusing on the dealership’s names, family names, and other pertinent terms. After countless refinements, I had amassed a potential list of over 12,000 pages of articles and ads.
The next step was to download these articles, a task complicated by the website’s sluggish performance and the time constraints of their access tiers. The “unlimited access” tier on the newspaper website would only last a mere 24 hours before I needed to renew at $20 a pop. Good thing it’s “unlimited”, right? 🙄
The Solution: Automation to the Rescue
Faced with the daunting task of destroying my wrists from 100,000+ clicks, I turned to the power of automation. I harnessed the capabilities of web scraping and scripting to streamline the data collection process. I created 3 different scripts to aid in my quest: The Gatherer, The Link Extractor, and The Downloader.
The Gatherer
After executing a search for a topic of interest (like “Soo Machine”), my first script would tirelessly navigate through each page of search results and bookmark each article to the website’s “filebox”. The website’s filebox was a storage area where documents were marked and set aside for later use. This process helped avoid duplicate articles since my search terms would often overlap. The code that performed this work was a simple Tampermonkey UserScript. The script clicked the Add to My Filebox button next to each article, navigated to the next page, and repeated the process.
The scripts and code presented here were developed in collaboration with Gemini. While I aimed for efficiency in completing my project, there might be room for further optimization and bug fixes. Feel free to utilize and adapt this code as a starting point for your own endeavors.
[Javascript] AddToMyFileboxLinks UserScript
// ==UserScript==
// @name Auto Add to My Filebox and 'Click' Next Page
// @namespace https://sooeveningnews.newsbank.com
// @version 1.0
// @description Automatically clicks "Add to My Filebox" links and navigates to the next page
// @author Kyle Niewiada
// @match https://sooeveningnews.newsbank.com/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
async function clickAddToMyFileboxLinks() {
const links = document.querySelectorAll('a');
links.forEach(link => {
if (link.textContent.trim() === 'Add to My Filebox') {
link.click();
}
});
}
function waitForNoAddToMyFileboxLinks() {
return new Promise((resolve, reject) => {
const intervalId = setInterval(() => {
const allLinks = document.querySelectorAll('a');
const remainingLinks = Array.from(allLinks).filter(link =>
link.textContent.trim() === 'Add to My Filebox'
);
// Check for timeout error dialog
const timeoutDialog = document.querySelector('div[role="dialog"][aria-labelledby="ui-dialog-title-timeoutMsg"]'); // Adjust selector if needed
if (timeoutDialog) {
clearInterval(intervalId);
reject(new Error("Timeout error dialog detected"));
return; // Stop further execution within this function
}
if (remainingLinks.length === 0) {
clearInterval(intervalId);
resolve();
}
}, 1000);
});
}
function clickNextPageLink() {
const nextPageListItem = document.querySelector('li.page-next');
if (nextPageListItem) {
const nextPageLink = nextPageListItem.querySelector('a');
if (nextPageLink) {
nextPageLink.click();
} else {
console.log("No link found under the 'Next Page' button.");
}
} else {
console.log("No 'Next Page' button found.");
}
}
// Main execution flow (wrapped in an event listener)
window.addEventListener('load', async () => {
await clickAddToMyFileboxLinks();
await waitForNoAddToMyFileboxLinks();
clickNextPageLink();
});
})();
The Link Extractor
Once every file of interest was in my filebox, I had to find a way to download them. Each result in my filebox contained a link that would take me to the real article, assuming I had already paid for access.
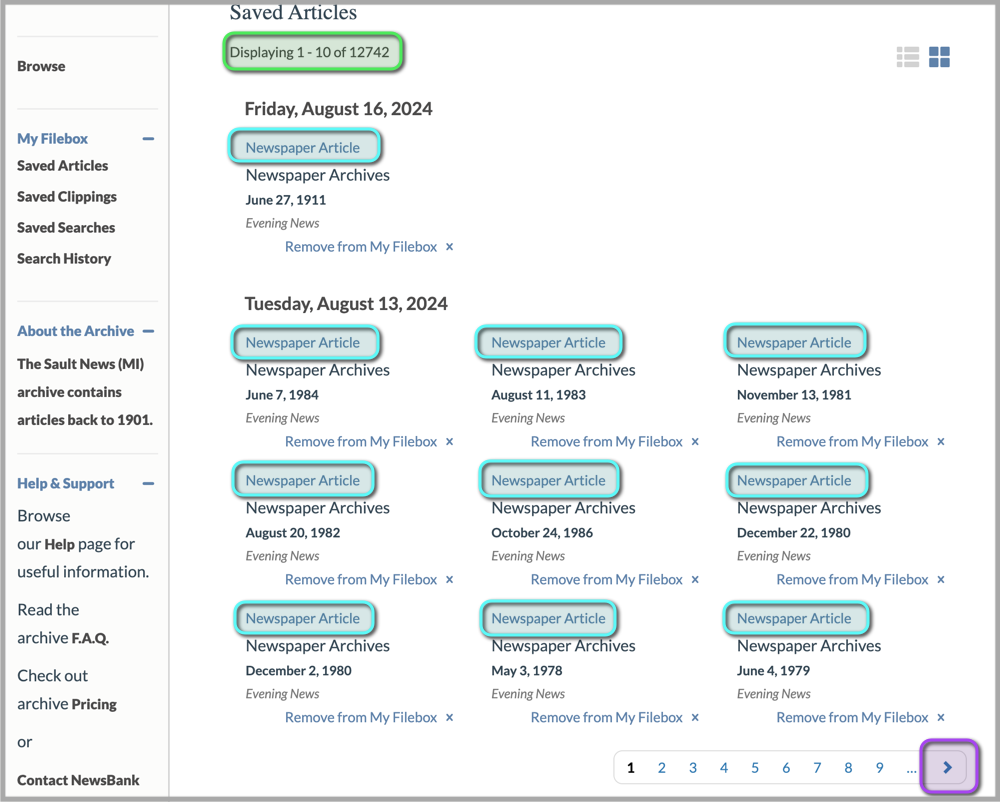
Instead of waiting to collect the links during my paid access, I figured I could be more efficient by copying all of the article links in from my filebox in advance. I wrote my second script to navigate through my entire filebox, page by page, and save the direct links to each article page. This little maneuver to collect all links in my filebox took 3 hours. ⌛️
[Javascript] Auto-Save Newspaper Article Links UserScript
// ==UserScript==
// @name Auto-Save Newspaper Article Links
// @namespace https://sooeveningnews.newsbank.com
// @version 1.0
// @description Automatically download the URLs to Newspaper Article pages.
// @author Kyle Niewiada
// @match https://sooeveningnews.newsbank.com/my-filebox/saved-articles*
// @require https://raw.githubusercontent.com/eligrey/FileSaver.js/master/dist/FileSaver.min.js
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Function to log URLs
function logNewspaperArticleLinks() {
let allLinks = document.querySelectorAll('a');
let count = 0;
let urls = []; // Array to store URLs
allLinks.forEach(link => {
if (link.textContent.trim() === "Newspaper Article") {
console.log(link.href);
urls.push(link.href); // Add URL to the array
count++;
}
});
console.log("Total Newspaper Article Links:", count);
// Create a blob from the URLs
let blobContent = urls.join('\n'); // Join URLs with newlines
let blob = new Blob([blobContent], {type: "text/plain;charset=utf-8"});
// Get the page number
let pageNumberSpan = document.querySelector('.page-current');
let pageNumber = pageNumberSpan ? pageNumberSpan.textContent.trim() : "1"; // Default to 1 if not found
// Pad the page number with zeros (e.g., 0001, 0002, ...)
let paddedPageNumber = pageNumber.padStart(4, '0');
// Save the blob with page number suffix
saveAs(blob, `newspaper_article_links_page_${paddedPageNumber}.txt`);
}
function clickNextPageLink() {
const nextPageListItem = document.querySelector('li.page-next');
if (nextPageListItem) {
const nextPageLink = nextPageListItem.querySelector('a');
if (nextPageLink) {
nextPageLink.click();
} else {
console.log("No link found under the 'Next Page' button.");
}
} else {
console.log("No 'Next Page' button found.");
}
}
// Main execution flow (wrapped in an event listener)
window.addEventListener('load', () => {
logNewspaperArticleLinks();
clickNextPageLink();
});
})();
The Downloader
Leveraging Python and the Selenium web automation framework, I built a third script to orchestrate the downloading process of each article from the links I had just collected. I purchased the paid access to the archive and started my code up. The script opened each saved link in Firefox, clicked the download buttons for the article, and watched the download folder for a new file to appear. Once the download started, the script would navigate to the next article link and begin the next download.
To keep things manageable with my limited late-night coding windows, I opted for a single-threaded approach, downloading one article at a time. While not the fastest method, I didn’t feel like dealing with the fallout of multithreaded edge cases. I didn’t want to miss a single file, and I didn’t want the website to flag me for downloading too quickly.
[Python] Article Downloader with Firefox Marionette
import marionette_driver
from marionette_driver.marionette import Marionette
import time
import psutil
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import NoSuchElementException
import inspect
from datetime import datetime
import subprocess
import os
import logging
import socket
import urllib.request
import sys
# Note 1: Before running, launch Firefox in marionette mode similar to this:
# /Applications/Firefox.app/Contents/MacOS/firefox --marionette
# We attach to an existing instance to make manual intervention easier.
# Note 2: I suggest changing your downloads directory in the web browser since the
# script watches for changes in the downloads directory. If you download a file
# while the script is running, it will think that's the file it's waiting for and
# move onto the next link.
# Path to the text file containing the links. One link per line.
links_file_path = 'links.txt'
# Get your Downloads directory path
downloads_dir = os.path.expanduser('~/Downloads/firefox_article_downloads')
# Firefox Marionette port
marionette_port = 52449
# Healthcheck.io ping URL to monitor the script's progress
# https://healthchecks.io/docs/http_api/
healthcheck_ping_url = "<INSERT_YOUR_OWN_HEALTHCHECK_IO_PING_URL_HERE>"
# Parse command-line arguments for start_line
if len(sys.argv) < 2:
print("Error: Please provide a starting line number as a command-line argument.")
exit(1)
# Configurable starting line number (1-based index to make it match the log messages. Easier to restart)
try:
start_line = int(sys.argv[1]) - 1 # Adjust for 0-based indexing
except ValueError:
print("Error: Invalid starting line number. Please provide an integer.")
exit(1)
# Function to get the current line number
def lineno():
return inspect.currentframe().f_back.f_lineno
# Set up logging
logging.basicConfig(filename='download_script.log', level=logging.INFO, format='%(asctime)s - %(message)s')
# Find the process ID and Marionette port of your existing Firefox instance
for proc in psutil.process_iter(['pid', 'name', 'cmdline']):
if proc.info['name'] == "firefox" and "--marionette" in proc.info['cmdline']:
firefox_pid = proc.info['pid']
for arg in proc.info['cmdline']:
if arg.startswith("--marionette-port"):
marionette_port = int(arg.split("=")[1])
break
break
else:
message = "Error: No running Firefox instance found with Marionette enabled."
print(message)
logging.error(message)
exit(1)
# Connect to the Marionette server using the Firefox process ID and port
client = Marionette(port=marionette_port, host='localhost', firefox_pid=firefox_pid)
client.start_session()
client.timeout.page_load = 60
# Get the original window handle (the main Firefox window)
original_window = client.current_window_handle
# Function to retry navigating to a link a specified number of times
def navigate_with_retries(client, link, line_number, total_lines, max_retries=3):
for attempt in range(1, max_retries + 1):
try:
client.navigate(link)
return # Navigation successful, exit the function
except BaseException as error:
timestamp = datetime.now().strftime("%b %d %H:%M:%S")
if attempt < max_retries:
message = f"{line_number:05d}/{total_lines:05d}: Navigating timed out. Retrying {attempt}/{max_retries}..."
print(timestamp, message)
logging.error(message)
logging.error(error)
time.sleep(1) # Wait before retrying
else:
message = f"{line_number:05d}/{total_lines:05d}: Navigating failed after {max_retries} attempts."
print(timestamp, message)
logging.error(message)
logging.error(error)
raise # Re-raise the exception after all retries fail
# Read links from the file
with open(links_file_path, 'r') as file:
links = file.read().splitlines()
total_lines = len(links)
# Validate start_line
if start_line < 0 or start_line >= total_lines:
print("Error: Invalid line number. Please ensure it is within the valid range.")
exit(1)
# Iterate through the links, starting from the configured line
exception_count = 0
for i, link in enumerate(links[start_line:]):
timestamp = datetime.now().strftime("%b %d %H:%M:%S")
line_number = i + start_line + 1
message = f"Line {line_number:05d}/{total_lines:05d}: Opening URL: {link}"
print(timestamp, message) # Print to console
logging.info(message) # Log the message
try:
urllib.request.urlopen(healthcheck_ping_url, timeout=10)
except socket.error as e:
# Log ping failure here...
timestamp = datetime.now().strftime("%b %d %H:%M:%S")
message = f"Ping failed: %s" % e
print(timestamp, message) # Print to console
logging.info(message) # Log the message
navigate_with_retries(client, link, line_number, total_lines)
while True:
try:
# Wait for the page to load (adjust timeout as needed)
WebDriverWait(client, 1).until(EC.presence_of_element_located((By.TAG_NAME, 'body')))
# Enable the next line before I go to bed to decrease the chances of the website erroring out due to us trying to download a file before it's ready.
# time.sleep(3)
# Find the download button using the ID attribute
download_button_1 = WebDriverWait(client, 5).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "[id='clip-download-click-target']"))
)
# Get the list of files in the Downloads directory before the click
before_download_files = set(os.listdir(downloads_dir))
# Click the download button
download_button_1.click()
# Enable the next line before I go to bed to decrease the chances of the website erroring out due to us trying to download a file before it's ready.
# time.sleep(3)
# Find the download button using the ID attribute
download_button_2 = WebDriverWait(client, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "[id='download_page_form_submit_button']"))
)
# Click the download button
download_button_2.click()
# Wait for a new file to appear in the Downloads directory
while True:
after_download_files = set(os.listdir(downloads_dir))
new_files = after_download_files - before_download_files
# Confirm the webpage is still there after the click. Sometimes it errors out and crashes.
WebDriverWait(client, 1).until(EC.presence_of_element_located((By.TAG_NAME, 'body')))
if new_files:
# A new file has started downloading
new_file = new_files.pop()
timestamp = datetime.now().strftime("%b %d %H:%M:%S")
message = f"Line {line_number:05d}/{total_lines:05d}: Download started: {new_file}"
print(timestamp, message) # Print to console
logging.info(message) # Log the message
break # Exit the inner loop
time.sleep(1) # Check every second
break # Exit the outer loop
except BaseException as error:
exception_count += 1
timestamp = datetime.now().strftime("%b %d %H:%M:%S")
message = f"Line {line_number:05d}/{total_lines:05d}: Download button not found yet for {link}. Waiting..."
print(timestamp, message) # Print to console
logging.error(message) # Log the error message
logging.error(error) # Log the error message
time.sleep(1)
if exception_count % 10 == 0:
navigate_with_retries(client, link, line_number, total_lines) # This reloads the current tab
# If I didn't notice the script repeatedly failing, and the script didn't recover yet, get my attention by having my computer talk to me.
if exception_count % 30 == 0:
subprocess.call(["say", "Hello. Are you there? I could really use some help. Something doesn't look right."])
# Reset the exception count after processing each link
exception_count = 0
# No need to stop the Marionette session or close Firefox since we're attached to an existing instance
The Challenges: Troubleshooting and Optimization
My late-night coding sessions were not without their hiccups. I encountered URL timeouts, download race conditions, and other unexpected obstacles. But with each challenge came an opportunity to learn and refine my approach.
I added error handling to ensure the script wouldn’t get stuck on a problematic link. I was able to achieve a download rate of 275–325 articles per hour. In a perfect world, it would have taken just under two days to completely download all articles. However, due to a complication on the first overnight run, my download task stretched into three days. 💸
Here is my script in action. The download process usually starts before the webpage gets a chance to load the article image.
Occasionally, my script would freeze when the website returned an error. I tried to combat this by adding additional error handling, but it seemed like the download script continued to find new ways to stall. I still hadn’t solved every hiccup by the second day of downloading, so I decided to pivot. Given that my access was time-limited, and we were almost halfway through downloading the articles, I shifted my efforts from proactive to reactive error handling.
My new reactive approach was to monitor the script’s download cadence. I implemented a clever “heartbeat” mechanism using the Healthchecks.io API. After every download, the script would ping the server. If the script failed to check in after a few minutes, it would indicate a potential stall. The website would then send me an alert on my phone, allowing me to intervene and keep the process running smoothly.
This new approach worked well. After 56 hours of downloading, I had successfully collected all 12,742 articles. Now, the real challenge was about to begin: figuring out how to process this mountain of data. 🏔️😵💫
The Transformation: Preparing Data for AI Analysis
Here’s how I see it. I have 3 options to process this data:
- Read through all 12,000 pages for the next 6 months. 📚
- Hire a researcher to do it for me. 💰
- Use AI to parse through the data and extract the information I want. 🤖
I chose option 3.
With my digital treasure trove of articles downloaded, it was time to prepare the data for analysis. I used OCR (Optical Character Recognition) software to convert the scanned newspaper pages into searchable text.
Originally, I had planned on using ocrmypdf which utilizes the Tesseract OCR engine. But I found in testing that I could get far better accuracy using the OCR engine from ABBYY FineReader instead.
Today, ABBYY FineReader allows for monthly subscriptions. Short enough to complete my OCR task.
Luckily, FineReader supports batch folder processing, making it easy to OCR large volumes of files. After a bit of testing, I dialed in my settings and started the task. The batch job pegged my old Intel processor at 100% CPU utilization for nearly 48 hours before it finished processing the 12,000 articles. 🔥🖥️😭
I was pleasantly surprised by the results. While some articles were challenging to read, the OCR software did a remarkably good job extracting the text. There were errors, of course. But I was only planning to go through every page if absolutely necessary.
I backed up the new OCR’d files and moved on to the next step for processing.
The Tumble: NotebookLM and its Limits
Earlier this year, while watching the 2024 Google I/O event, they announced the wide availability of a new tool called NotebookLM. It’s an AI-powered notebook that can analyze and summarize vast amounts of text data (other mediums in the future). Once everything is processed, you can ask the tool any question that you want (like a chatbot), and it will try to answer using only the source data provided. This is one of the most practical applications of AI I’ve seen all year. 📈
Unlike other AI tools, NotebookLM is source-grounded with inline citations. The chances of hallucinations occurring are very low. All responses require a citation, allowing me to quickly verify any claims. I knew this was the perfect solution for my large-data problem. But how could I apply it to my 12,000 articles?
Today, NotebookLM has a limit of 50 sources. So let’s just throw all 12,000 articles into a single file, right? Nope! Each source is limited to 200 MB and must contain fewer than 500,000 words. This meant I needed to get creative with my data processing if I wanted to maximize the amount of information I could upload to NotebookLM.
Here’s my problem. If I combine all 12,000 articles into a single file and then split them based on size and word count, I get roughly 88 files. That’s not going to work. I needed to get that number down to 50 or lower.
The Reduction: Crafting a Dataset for AI Analysis
Not wanting to lose any valuable information from my new dataset, I employed another script to strategically extract specific articles based on keywords and variants. This is what I came up with based on priority, and how infrequently I thought the terms would appear. If they were less common, I wanted to gather everything I could on the topic.
- George Ingham
- Robert Morrison
- Roy Hollingsworth
- Bud Mansfield
- Hollingsworth Auto
- Mansfield Auto
- Soo Machine
If my script picked up on an article page containing the keywords, it would move the file into a new staging folder. The idea is that I’d keep running this script, adding in keywords, until I had a manageable number of files to work with.
[Python] Move PDF Files Containing a Keyword
import os
import shutil
from tqdm import tqdm
try:
from pypdfium2 import PdfDocument
except ImportError:
print("pypdfium2 is not installed. Please install it using 'pip install pypdfium2'")
exit(1) # Exit the script if pypdfium2 is not available
# Get user input or set default values
directory_path = "pdf_downloads"
search_text = input("Enter the text to search for: ") or "your_search_text"
destination_folder = "pdf_downloads_selected"
def move_pdfs_with_text(directory, search_text, destination_folder, initial_pages_to_check=5):
"""
Moves PDF files containing specific text to a destination folder,
with a progress bar, optimized text extraction, and using pypdfium2 for PDF parsing.
Args:
directory: The directory to search for PDF files.
search_text: The text to search for within the PDF files.
destination_folder: The folder to move matching PDF files to.
initial_pages_to_check: Number of initial pages to check for the search text.
"""
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
pdf_files = [f for f in os.listdir(directory) if f.endswith(".pdf")]
for filename in tqdm(pdf_files, desc="Searching PDFs", unit="file"):
filepath = os.path.join(directory, filename)
with open(filepath, "rb") as pdf_file:
pdf = PdfDocument(pdf_file)
num_pages = len(pdf)
# Check initial pages first
pdf_text = ""
for page_num in range(min(initial_pages_to_check, num_pages)):
page = pdf[page_num]
pdf_text += page.get_textpage().get_text_bounded()
if search_text.lower() not in pdf_text.lower():
# If not found in initial pages, check remaining pages
for page_num in range(initial_pages_to_check, num_pages):
page = pdf[page_num]
pdf_text += page.get_textpage().get_text_bounded()
if search_text.lower() in pdf_text.lower():
break # Stop checking once found
if search_text.lower() in pdf_text.lower():
print(f"Found text in: {filename}")
shutil.copy(filepath, destination_folder)
os.remove(filepath)
move_pdfs_with_text(directory_path, search_text, destination_folder)
This was a good start. But I was still looking at a dataset that was too large for NotebookLM. This process only shaved off a few thousand candidates. I needed to further refine my dataset to meet NotebookLM’s requirements.
The median word count for all 12,000 files was approximately 4,000 words per page. If I used the word count as a limiting factor (50 * 500,000 words), I would need to reduce my total word count to 25 million words (or ~6,250 pages from my dataset) before I stood a chance of uploading them all.
The biggest offender that caused me to go over my limit was always the last extraction of articles that contained “Soo Machine”. After combing through this last dataset, I realized a large portion of these articles were filled with less important classified ads or rummage sale notices. They were originally included in my dataset because I grabbed every single article that mentioned “Soo Machine”.
I ran another extraction on the “Soo Machine” group and dropped any articles that contained rummage or classified ads. This gave me just enough wiggle room where my dataset should fit when I upload it to NotebookLM.
I created two additional Python scripts. The first script merged every article page (keeping them in chronological order) into one single file. Then, the second script divided this large file back into smaller files, ensuring each new file met NotebookLM’s size and word count restrictions.
[Python] Merge all PDF files together (in order)
import os
import glob
from PyPDF2 import PdfMerger
import multiprocessing
# Merge all PDF files in a directory together based on the filename for The Evening News
# Assumes the filenames are in the format: "Evening_News_YYYY-MM-DD_Page.pdf"
# Page numbers are not zero-padded (`1` vs `10`), so we need to parse them as an integer to sort properly
# Sometimes the download names are duplicated at the source so they end in (1) or (2) after we download them. We ignore this part of the filename when sorting and assume there are different scans that were uploaded.
def merge_pdf(filename):
merger = PdfMerger()
merger.append(filename, 'rb') # Open in 'rb' (read binary) mode
# Instead of returning the merger, write the merged PDF to a temporary file for speed
temp_filename = f"{filename}_temp.pdf"
with open(temp_filename, "wb") as temp_file:
merger.write(temp_file)
return temp_filename # Return the temporary filename
if __name__ == "__main__":
pdf_directory = "pdf_files" # Directory containing the PDF files
os.chdir(pdf_directory)
pdf_files = glob.glob("*.pdf")
def extract_date_and_page(filename):
date_str, page_str = filename.split("_")[2:] # Extract date and page parts
year, month, day = map(int, date_str.split("-"))
page_str = page_str.split("(")[0].split(".")[0] # Remove parentheses and extension
page = int(page_str)
return year, month, day, page # Return tuple for sorting
pdf_files.sort(key=extract_date_and_page) # Sort using the extracted page number
with multiprocessing.Pool() as pool:
temp_filenames = pool.map(merge_pdf, pdf_files)
final_merger = PdfMerger()
for temp_filename in temp_filenames:
final_merger.append(temp_filename)
with open("Combined_files.pdf", "wb") as output_file:
final_merger.write(output_file)
# Clean up temporary files
for temp_filename in temp_filenames:
os.remove(temp_filename)
[Python] Split all PDFs by word count and file size
import os
import PyPDF2
import hashlib
import time
import re
from tqdm import tqdm
import textstat
# Splits up PDF files based on word count and file size in order to fit within NotebookLM's limits.
# Usually we're only splitting the master `Combined_files.pdf` file of _all_ PDF files.
# But this will still work for multiple files if needed.
# Note: Make sure to update the `directory_path` at the bottom of this script
def split_pdfs_in_directory(directory_path, max_size_mb=190, max_word_count=500_000, word_count_buffer=70_000):
"""
Splits all PDF files in a directory based on size or word count.
Args:
directory_path: The path to the directory containing PDF files.
max_size_mb: The maximum allowed size for each split file in megabytes.
max_word_count: The maximum allowed word count for each split file
word_count_buffer: A buffer to ensure the final word count stays below the limit after processing
"""
max_size_bytes = max_size_mb * 1024 * 1024 # Convert MB to bytes
effective_max_word_count = max_word_count - word_count_buffer
for filename in os.listdir(directory_path):
if filename.endswith(".pdf"):
filepath = os.path.join(directory_path, filename)
file_size = os.path.getsize(filepath)
if file_size > max_size_bytes:
print(f"Splitting {filename} based on size...")
try:
split_pdf(filepath, max_size_bytes, effective_max_word_count)
except Exception as e:
print(f"Error splitting {filename}: {e}")
else:
os.remove(filepath)
print(f"Deleted original file: {filename}")
def split_pdf(filepath, max_size_bytes, max_word_count):
"""
Splits a PDF file into smaller files until each is less than max_size_bytes or max_word_count.
Args:
filepath: The path to the PDF file to split.
max_size_bytes: The maximum allowed size for each split file in bytes.
max_word_count: The maximum allowed word count for each split file
"""
with open(filepath, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
num_pages = len(pdf_reader.pages)
output_pdf_writer = None
output_pdf_filename = None
current_part = 1
current_word_count = 0
# Progress bar setup based on number of pages
pbar = tqdm(total=num_pages, desc="Splitting Progress")
for page_num in range(num_pages):
page = pdf_reader.pages[page_num]
# Word counting using textstat
page_text = page.extract_text()
page_word_count = textstat.lexicon_count(page_text, removepunct=True)
# Handle pages with word count exceeding the limit by starting a new part
if current_word_count + page_word_count > max_word_count:
if output_pdf_writer is not None:
_save_part(output_pdf_writer, output_pdf_filename, current_word_count)
output_pdf_writer = None
current_part += 1
current_word_count = 0
if output_pdf_writer is None:
unique_id = hashlib.md5((filepath + str(time.time())).encode()).hexdigest()[:6]
output_pdf_filename = f"{os.path.splitext(filepath)[0]}_part{current_part}_{unique_id}.pdf"
output_pdf_writer = PyPDF2.PdfWriter()
print(f" - Creating new part: {output_pdf_filename}")
# Directly add the page to the output writer
output_pdf_writer.add_page(page)
current_word_count += page_word_count
# Periodically check file size to avoid exceeding the limit
if page_num % 10 == 0: # Adjust the frequency as needed
_check_and_save_if_needed(output_pdf_writer, output_pdf_filename, max_size_bytes, current_word_count)
if output_pdf_writer is None:
current_part += 1
current_word_count = 0
pbar.update(1) # Update progress bar based on pages processed
# Save the last part if it exists
if output_pdf_writer is not None:
_save_part(output_pdf_writer, output_pdf_filename, current_word_count)
pbar.close() # Close the progress bar
def _save_part(output_pdf_writer, output_pdf_filename, current_word_count):
temp_filename = output_pdf_filename + ".tmp"
# If the temp file exists, rename it to the final filename
if os.path.exists(temp_filename):
os.rename(temp_filename, output_pdf_filename)
with open(output_pdf_filename, 'wb') as output_pdf_file:
output_pdf_writer.write(output_pdf_file)
output_file_size = os.path.getsize(output_pdf_filename)
print(f" - Saved part: {output_pdf_filename} (Size: {output_file_size} bytes, Words: {current_word_count})")
# Clean up all temporary files in the directory
for filename in os.listdir(os.path.dirname(output_pdf_filename)):
if filename.endswith(".tmp"):
os.remove(os.path.join(os.path.dirname(output_pdf_filename), filename))
def _check_and_save_if_needed(output_pdf_writer, output_pdf_filename, max_size_bytes, current_word_count):
temp_filename = output_pdf_filename + ".tmp"
# Write to the temporary file
with open(temp_filename, 'wb') as temp_pdf_file:
output_pdf_writer.write(temp_pdf_file)
temp_file_size = os.path.getsize(temp_filename)
if temp_file_size > max_size_bytes:
# If the temporary file exceeds the size limit, save it as the final file
_save_part(output_pdf_writer, output_pdf_filename, current_word_count)
output_pdf_writer = None # Reset for the next part
if __name__ == "__main__":
directory_path = "pdf_files" # Directory containing the PDF files to split (usually only one file is getting split, but it will work for multiple)
split_pdfs_in_directory(directory_path)
With a bit of trial and error, I eventually found the sweet spot. I was able to reduce the number of files from 88 to 46, each containing a manageable amount of data that I thought would fit within NotebookLM’s limits. With my data meticulously organized, I fed it into NotebookLM.
I hit a small snag where some files that I uploaded were still breaking NotebookLM’s word-count rule, so I continued lowering my word-count limit until each file worked with NotebookLM; ~430,000 words each.
Previously, NotebookLM only worked with PDFs containing OCR text, which it would extract and analyze, discarding the original file. As of August 22, 2024, NotebookLM now supports image-only PDFs, understanding photos, drawings, charts, and even handwriting.
This enables the AI to visually analyze elements like ad placement and connecting content to specific businesses—something difficult with text-only extraction. While this feature currently doesn’t work on PDFs with existing OCR text, the developers are working on merging these functionalities.
The Payoff: Unlocking Lost Secrets with NotebookLM
The files were uploaded, and the data processed. I began my waves of questions with the notebook. The AI’s ability to analyze and summarize vast amounts of text in its answers was astounding. It extracted key events and relationships. With a little prompt engineering, I was able to construct a comprehensive timeline of the dealership, learn about the founders, and uncover many fascinating details.
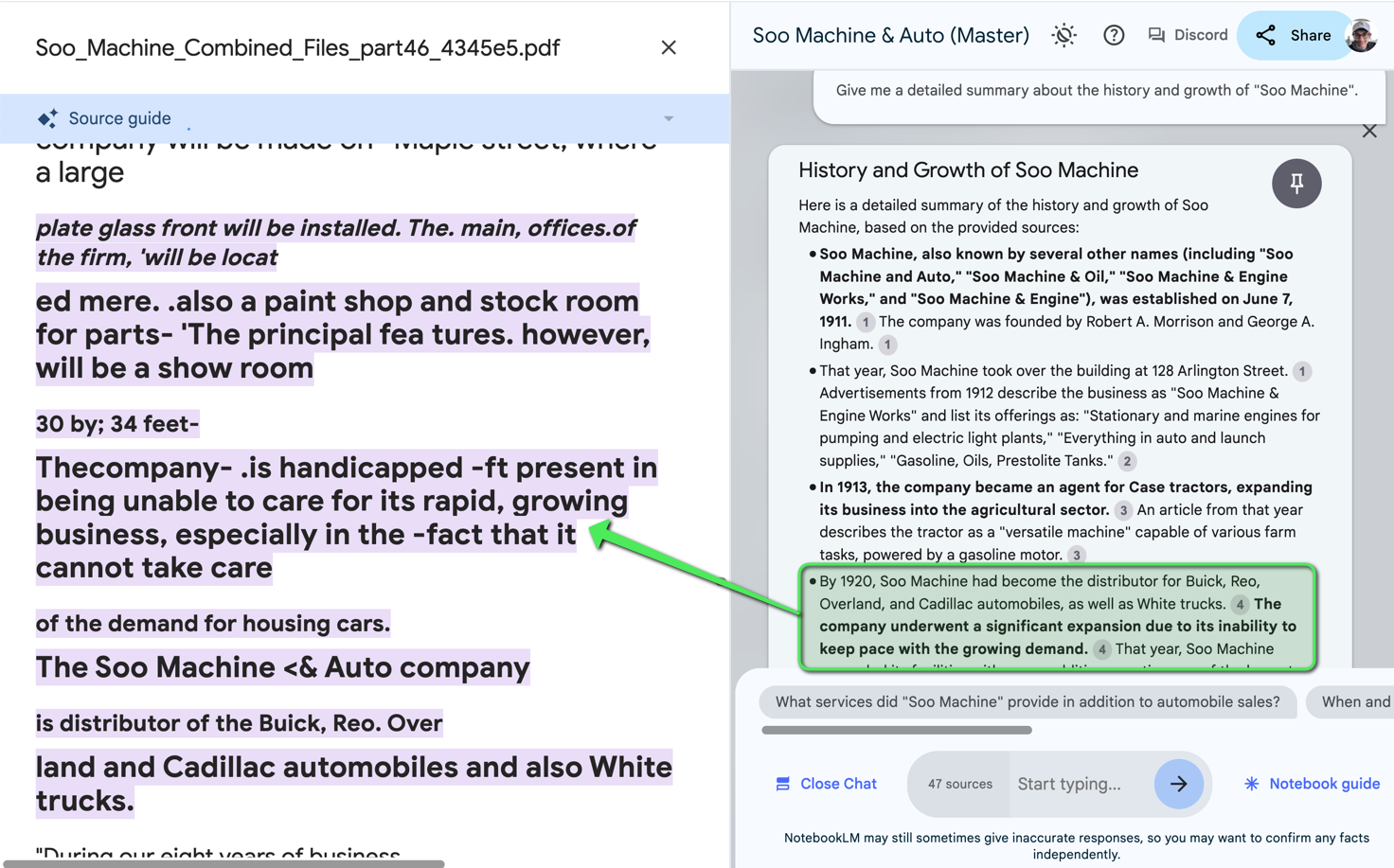
It worked. ✨ Without any delay, I present my findings of Soo Machine & Auto Co.
Soo Machine & Auto Co.: A Brief History
NotebookLM served as a valuable tool in analyzing data from the Chippewa County Historical Society and 12,000 articles from The Evening News. While it provided a solid foundation for my research, I also contributed significantly to the analysis and interpretation of the findings. The following summary highlights the most significant discoveries, incorporating both NotebookLM’s insights and my own original research.
1910s
Soo Machine & Engine Works was an automotive business located in Sault Ste. Marie, Michigan. Founded in 1911 by Robert A. Morrison and George W. Ingham, the company started as a machine shop specializing in heavy machine work and offering blacksmith services. In its early years, the company operated at 128 Arlington Street briefly under the name Soo Machine and Engine Works. In 1912, the company moved to a new location at 128 Portage Ave. (built by Marshall N. Hunt) and officially incorporated as Soo Machine & Auto Co. Both buildings still stand today.
Robert Morrison, one of the co-founders, was a skilled machinist and the manager of the Soo Machine & Auto Co. He is credited with playing a crucial role in the company’s success, as he ensured it was fully equipped to handle various engine and machine repairs, specializing in gas engines and launch machinery. Morrison frequently traveled on business, attending auto shows and visiting cities like Chicago and Milwaukee. On October 4, 1909, Robert Morrison (1880) married Miss Violet May Parsons (~1883).

George (Whithouse) Ingham, the other co-founder, was the president of Soo Machine & Auto. Prior to this position, he was awarded patents for a “steam-boiler” (US760126A) in 1904 and a “lubricator” (US843536A) in 1907.
In 1913, George Ingham resigned as president of Soo Machine & Auto and as chief engineer of the Pittsburgh Steamship Company. He relocated to Winnipeg.
By 1915, Soo Machine & Auto had already advertised selling Rambler Cross-Country, REO the Fifth, and the Jeffery cars.
In February 1915, Robert Morrison, the manager at Soo Machine and Auto Co., hired Roy D. Hollingsworth (who would later become the owner of the company) as a car salesman for $100 per month. When the directors learned about the unauthorized hire, they instructed Morrison to fire Hollingsworth and not pay him. However, at the next month’s meeting, they discovered Hollingsworth was still working, without pay, and had sold $4,000 worth of new cars in the middle of winter. Astonished by his salesmanship during a time when people rarely bought cars, the directors questioned both Morrison and Hollingsworth before ultimately rehiring him and paying him for two months’ salary.
By 1917, the company was the local dealer for six car brands: Jeffreys, Chevrolet, Reo, Cadillac, Oldsmobile, and White. It also sold Firestone and Goodyear tires.
1920s
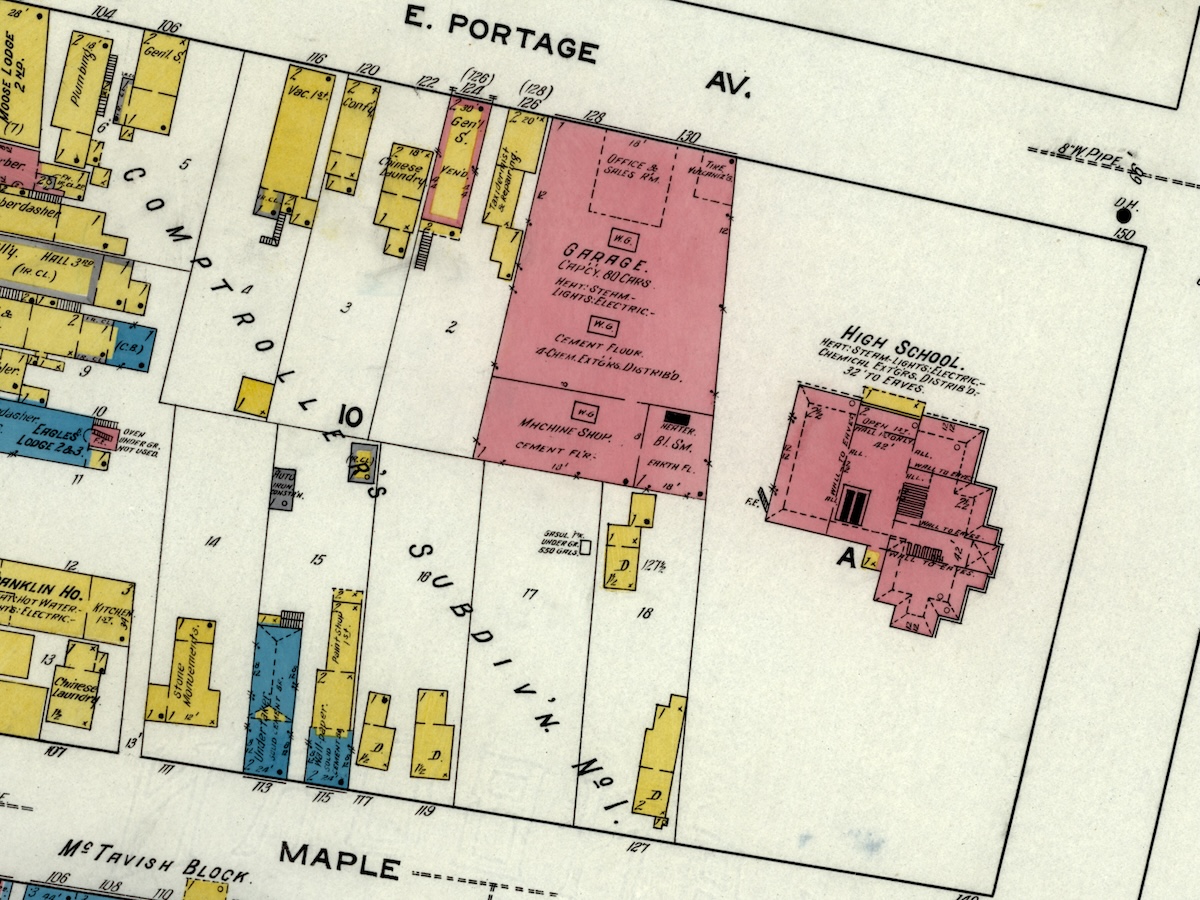
In 1920, Soo Machine & Auto Co. embarked on a major expansion project, investing $25,000 to expand its building on Portage Ave. south to Maple Street and construct a state-of-the-art facility. This created the largest garage in Michigan on a single floor at the time. The building covered most of a city block.
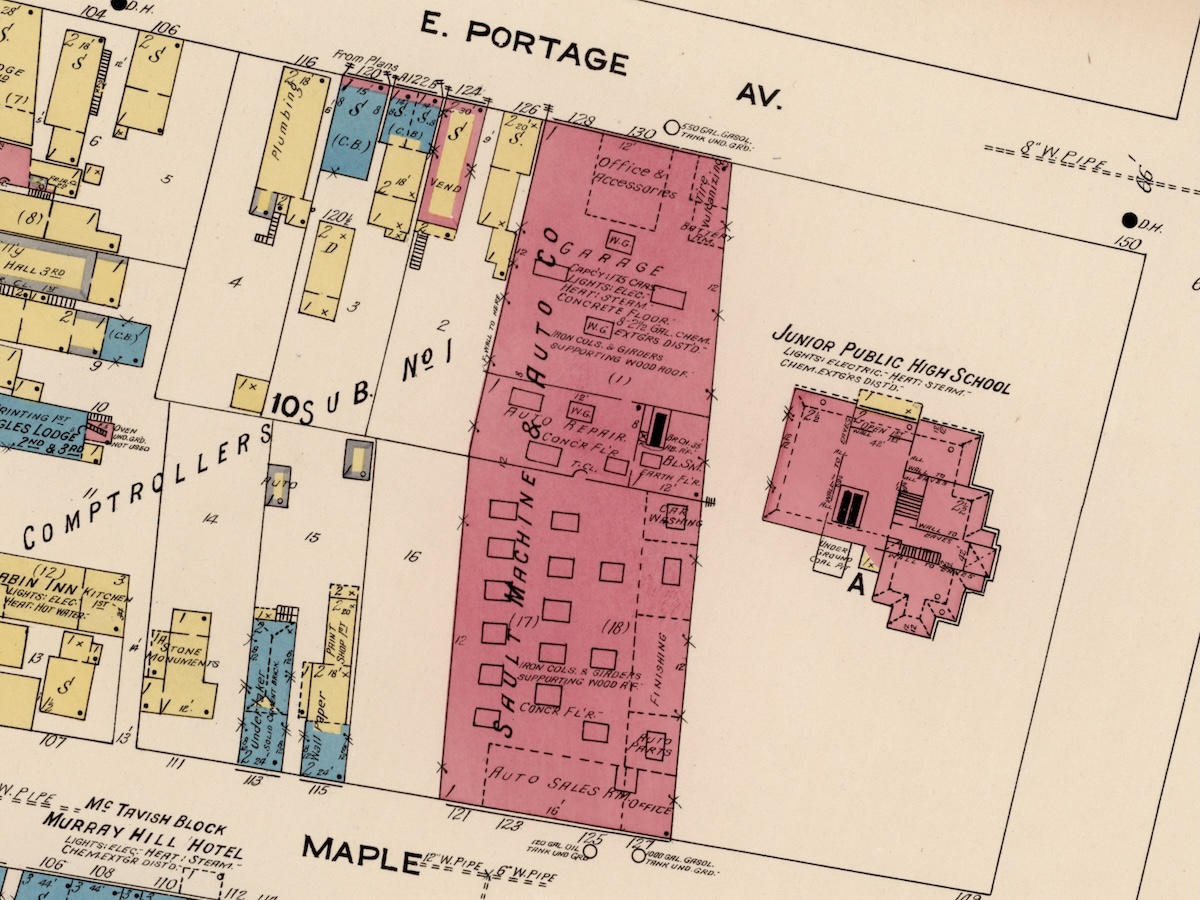
This move signaled a strategic shift for the company, providing a larger and more prominent location to accommodate its growing business. The new building boasted a spacious showroom for displaying their expanding inventory of automobiles, dedicated office space, and a well-stocked stockroom. The building still stands today.

On March 13, 1920, Soo Machine & Auto Co. took out an 8-page supplement to The Evening News. At the time, it was the largest ever paid advertisement in The Evening News. This supplement contained a variety of articles, photos, and advertisements showcasing the company’s offerings and services. It is now part of the public domain, and I have attached a copy for others to enjoy. I tried my best to OCR it, but the quality of the microfilm scan was poor.
Evening_News_1920-03-13_Supplemental.pdf
EDIT 2025-05-21: UPLINK has uploaded their own scan of this newspaper with higher quality images (but less readable text). Check it out here.
However, I reached out and obtained an uncompressed scan from them, which I’ve recompressed at a suitable resolution for reading here (~50 MB).
Throughout the 1920s, Soo Machine & Auto Co. adapted to the evolving automotive market, securing dealerships with several prominent car manufacturers. Building upon its existing partnerships with Jeffery, Buick, Chevrolet, Reo, Cadillac, Oldsmobile, and White trucks, the company expanded its offerings to include Paige automobiles. The company’s ability to secure dealerships with a diverse range of manufacturers highlights its strong reputation in the industry and its understanding of the growing demand for automobiles in the region.

Beyond its role as an automotive dealer, Soo Machine & Auto Co. became a central gathering place for the Sault Ste. Marie community. The sources describe the company as a place where “farmers would meet,” “bigwigs gravitated,” “sportsmen met,” and “weary businessmen” would gather. This confluence of community members transformed the company into a de facto community center, where local affairs, sporting events, and even political matters were discussed and debated. The company’s central location on Maple Street further contributed to its role as a community hub.
The 1920s brought a shift in leadership for the Soo Machine and Auto Company. Robert A. Morrison, a key figure since the company’s founding, departed in 1921, leaving behind a legacy of success that the public widely attributed to his leadership. Stepping into the managerial role was Thomas Chandler, president of the Edison Sault Electric Company. Meanwhile, Roy D. Hollingsworth’s influence continued to grow, setting the stage for his eventual presidency and the company’s future renaming in his honor.
By 1922, Soo Machine & Auto had advertised the availability of the luxury Packard cars. But the company stopped advertising Packard cars after 1925.

1930s
Navigating the Depression: While the sources don’t explicitly discuss how Soo Machine navigated the economic challenges of the Great Depression, they do suggest that the company remained in business during this period. Advertisements from the 1930s promoting car sales, such as those featuring the affordability of new Buicks and the availability of installment plans and radios, hint at the company’s efforts to adapt to the economic climate and attract customers.
The company briefly carried Pontiac cars from 1934 to ~1937. Several sources from late 1937 and 1938 mention that Soo Machine & Auto Co. had dropped the Pontiac agency to focus back on Buick sales. For instance, a 1938 article states, “There has been no Pontiac agency in the city since the Soo Machine & Auto company last year decided to concentrate its sales efforts to Buicks”. It wouldn’t be until 1958 that we would see the Pontiac line return to the dealership.
Community Engagement: Soo Machine continued to be a central point in the Sault Ste. Marie community throughout the 1930s. Advertisements indicate the company’s participation in local events and promotions. For example, a 1933 ad mentions a “School Year 1933-1934” event.
1940s
Limited Information: The sources provide very little information specifically about Soo Machine’s operations during the 1940s. This lack of detail makes it challenging to pinpoint highlights from this period. It’s possible that, like many businesses during wartime, Soo Machine may have faced constraints due to rationing, supply shortages, or manpower limitations imposed by World War II.

Post-War Transition: While specifics about the 1940s are scarce, an article from 1949 mentions Soo Machine hosting a display of the new Buick chassis, suggesting a return to normalcy and a focus on showcasing new car models as the nation transitioned out of the war years.
1950s
By the 1950s, Soo Machine and Auto Co.’s used car lot boasted a diverse selection, featuring everything from Buicks and Chevrolets to Dodges, Fords, GMCs, Hudsons, Mercurys, Nashes, Oldsmobiles, Plymouths, and Willys.
Roy D. Hollingsworth retired from Hollingsworth Auto Sales in 1956. Although he retired in 1956, he retained an interest in the firm until his death.

In 1952, Elmer Mansfield, who had retired from the U. S. Postal Service, started working at Soo Machine & Auto Co.
In 1957, Elmer’s son, Francis “Bud” Mansfield joined and brought the Pontiac line back to Soo Machine & Auto Co. This ended the 20-year Pontiac drought at the dealership.
In 1958, Soo Machine & Auto officially became a Pontiac dealership.
By the late 1950s, they were a dealer for Buick, Cadillac, GMC, Pontiac, and Opel.
1960s
In 1965, Soo Machine and Auto Co. changed its name to Hollingsworth Auto Sales, Inc., while maintaining the same ownership and management. Duncan Hollingsworth and Jerry Hollingsworth became the president and vice-president of the company, respectively. The brothers were the sons of Roy D. Hollingsworth, who had been a key figure in the company’s history.
In 1968, Hollingsworth Auto Sales, Inc. moved to a new 17,000 square-foot location on Business Spur I-75 and Three Mile Road (4001 I-75 Business Spur Sault Ste. Marie, MI 49783). The building still stands today.

The new building was strategically positioned at the northeast corner of City Limits Road and the I-75 Business Spur, a rapidly developing area then known as the “Miracle Mile”. This location provided enhanced visibility and accessibility for customers. The building occupied a 10-acre tract, providing ample space for future expansion. The car lot alone could accommodate 150 vehicles. A 50-foot wide canopy connected the showroom to a 12,000 square foot service and parts department, offering protection from the elements and convenience for customers.
The service department boasted 12 service stalls, making it one of the most modern automotive service centers in the region. The facility included a new factory-built paint booth, the second of its kind in the Upper Peninsula at the time, and renowned for its modern design.
The grand opening of the new building coincided with the company’s “50th anniversary” (but not really), celebrated over three days in May 1968. The event featured live music, refreshments, and numerous prizes to commemorate the occasion and express gratitude to loyal customers.
1970s
Throughout the 1970s, Hollingsworth Auto emphasized its commitment to customer service. Advertisements frequently mention “factory-trained mechanics,” “guaranteed satisfaction,” and a dedication to providing a positive car-buying experience. This customer-centric approach likely contributed to the company’s continued success.
While still involved in Hollingsworth Auto, Duncan and Jerry Hollingsworth established a new business venture, Hollingsworth Tires, between 1975 and 1976. Located near Hollingsworth Auto on Three-Mile Road, this expansion into tire sales and services reflected the brothers’ entrepreneurial spirit and their understanding of the automotive market’s needs.
In late 1975, Duncan Hollingsworth and Jerry Hollingsworth announced the sale of the dealership to Paul Braun and Francis (Bud) Mansfield. This change in ownership marked a turning point in the company’s history, though the Hollingsworth family remained involved in the business.
They announced that on January 3, 1976, Hollingsworth Auto Sales would start operating under the name Braun-Mansfield, Inc.
1980s
In 1980, Bud Mansfield purchased Paul Braun’s share of the business, becoming the sole owner of Braun-Mansfield. It was renamed to Francis M. Mansfield, Inc (F. M. Mansfield, Inc.).

Unfortunately, 50% of the firm’s business had been with Kincheloe Air Force Base, which was in the final stages of closing down. The base closure and continuing poor economic conditions of the “double-dip” recession in the early 1980s worked against F. M. Mansfield.
On November 13, 1981, F. M. Mansfield closed its doors to regular operations.
The closure marked the end of an era for Soo Machine & Auto, Hollingsworth Auto, Braun-Mansfield, and F. M. Mansfield—a company that had been a fixture in Sault Ste. Marie for decades. 🚗
A Legacy
For over half a century, Soo Machine and Auto wasn’t merely a place to buy cars or get them fixed; it was woven into the very fabric of Sault Ste. Marie life. Founded around 1911, its evolution into a community cornerstone was largely guided by the astute business acumen of Roy D. Hollingsworth. His success selling cars during the traditionally slow winter months challenged the prevailing business assumptions of the time and helped transform Soo Machine and Auto from a seasonal sales business to a year-round operation.
Hollingsworth’s contributions extended beyond the automotive realm. He was highly involved in community affairs, holding leadership roles in organizations like the Chamber of Commerce, Boy Scouts of America, Rotary Club, and Red Cross. He directed Civil Defense in Sault Ste. Marie during World War II and actively participated in the Republican Party. He was recognized for his dedication and leadership by figures like former Michigan Governor Chase S. Osborn.
“Soo Machine” may have changed names over the years – becoming Hollingsworth Auto Sales, then Braun-Mansfield, and finally F.M. Mansfield. But its legacy endures. It was the people behind those names – the dedicated employees at each iteration – who truly made the dealership a cornerstone of the community. “Soo Machine” evokes a sense of nostalgia, reminding us of a time when a local business, led by passionate individuals, could be more than just a place of commerce. It could be the heart of a community.
Dealership Name Changes
Here is a summary of the name changes that took place at this dealership over the years. There is sometimes an overlap period where both names are used in the newspapers.
-
Soo Machine & Engine Works
- July 22, 1911
- While first announced (as “Soo Machine Company”) on June 27, 1911, it wasn’t until July 22 that they put a notice in the newspaper that they were open to the public with the “Engine Works” name.
-
Soo Machine & Auto Co.
- July 18, 1912
- This aligns with the move from 128 Arlington St. to the new location at 128-130 East Portage Avenue.
- The first newspaper mention I found with their new incorporated name.
-
Hollingsworth Auto Sales, Inc.
- April 9, 1965
-
Braun-Mansfield, Inc.
- January 3, 1976
-
F. M. Mansfield, Inc.
- November 7, 1980
Important Individuals
Here is a list of important individuals associated with Soo Machine & Auto, Hollingsworth Auto, Braun-Mansfield, and F. M. Mansfield, along with their roles and years of activity. This was generated by NotebookLM from the sources I provided. I did my best to verify and resolve any information from the sources that were in conflict.
-
Robert A. Morrison
- Role: Co-founder, Manager, Treasurer
- Years Active: 1911-1921
-
Key Information:
- Established Soo Machine & Engine Works with George Whithouse Ingham on June 7, 1911.
- Hired Roy D. Hollingsworth in 1915.
- Served as manager until Clayton J. Schenk took over the role.
- Left the company in 1921.
-
George Whithouse Ingham
- Role: Co-founder, President (1911-1913)
- Years Active: 1911-March 1, 1913
- Key Information:
-
Roy Duncan Hollingsworth
- Role: Owner (1943-1964), President (1944-1964), Vice-President, Employee (1915-1956)
- Years Active: 1915-1956
-
Key Information:
- Considered a key figure who helped shape the company’s identity and success.
- Became president of the company in 1944.
- Retired from active involvement in 1956 but retained an interest in the business until his death.
- His sons, “Duncan” and “Jerry”, continued the family legacy in the automobile business.
-
Clayton J. Schenk
- Role: Secretary, Manager, Director
- Years Active: 1930s-unknown
-
Key Information:
- Former part-owner of the Marks-Schenk company.
- Became manager of Soo Machine & Auto after buying a considerable interest in the company.
- Elected as Secretary and Director by the board of directors.
- Possible middle name Joe, as his son was named Clayton Joe Schenk, Jr.
-
Edward Duncan Hollingsworth (Known as “Duncan Hollingsworth”)
- Role: President (1964-1976), Owner
- Years Active: ca. 1950s-1976
-
Key Information:
- Son of Roy D. Hollingsworth.
- Became president of the company, then known as Hollingsworth Auto Sales, in 1964.
- Sold share of the company in 1976.
-
Jerome L. Hollingsworth (Known as “Jerry Hollingsworth”)
- Role: Vice President (1964-1976), Owner
- Years Active: ca. 1950s-1976
-
Key Information:
- Son of Roy D. Hollingsworth.
- Served as vice president of Hollingsworth Auto Sales.
- Sold share of the company in 1976.
-
Francis “Bud” Mansfield
- Role: Sales Manager, Partner (1976-1980), Owner (1980-1981)
- Years Active: 1957-1981
-
Key Information:
- Started at the company in 1957.
- Later became sales manager.
- Purchased a 50% interest in the company alongside Paul Braun in 1976.
- Eventually became the sole owner in late 1980.
-
Paul J. Braun
- Role: Partner (1976-1980)
- Years Active: 1976-1980
-
Key Information:
- Detroit area district sales manager for Buick for 15 years.
- Purchased Hollingsworth Auto Sales with Francis “Bud” Mansfield in 1976.
- His involvement ended around November 6, 1980.
- Paul moved away and in 1981 bought Tinney Cadillac in Buffalo, New York.
Car Makes Carried
The following table lists verified car makes advertised by Soo Machine & Auto, Hollingsworth Auto, Braun-Mansfield, and F. M. Mansfield, along with the years they appeared in our sources. Please note that the absence of an advertisement for a specific car brand or year doesn’t necessarily mean Soo Machine didn’t sell it during that time. The sources, primarily advertisements and articles, cover several decades, and there may be gaps in the available records. Occasionally I indicate when a car brand was likely carried continuously throughout a specific period when there is overwhelming evidence.
- Buick: 1917-1981
- Cadillac: 1916, 1917, 1922, 1923, 1924, 1929, 1931, 1936, 1938, 1948, 1949, 1950, 1952, 1953, 1956, 1957, 1958, 1960, 1962, 1963, 1964, 1971, 1978, 1979 (Later article claims franchised since 1934.)
- Chevrolet: 1916, 1917
- GMC Trucks: 1931, 1937, 1939, 1946, 1947, 1949, 1951, 1953, 1957, 1962, 1971, 1978, 1979 (Later article claims franchising since 1929.)
- Hudson: 1925
- Jeep: 1962, 1968, 1971 (Later article claims franchising since 1964.)
- Jewett: 1923, 1924
- Jeffery: 1914, 1915, 1917
- LaSalle: 1929, 1930, 1931, 1936, 1939
- Marquette: 1929, 1930
- Oldsmobile: 1916, 1917, 1924, 1931
- Opel: 1959, 1973, 1975
- Overland: 1918-1926
- Paige: 1923, 1925, 1927
- Packard: 1922-1925
- Pontiac: 1934-1937, 1958-1981
- Rambler: 1911, 1912, 1913, 1962, 1963
- R-C-H: 1911
- REO: 1914, 1917, 1918, 1919, 1922, 1923, 1924, 1925, 1927
- White: 1917, 1919
The sources also indicate that Soo Machine & Auto sold Case tractors in 1917.
Information Bounties
While this digital excavation has unearthed a treasure trove of information, a few intriguing mysteries remain that I’d like to learn more. I am offering a few monetray bounties to anyone who can help uncover these unknowns below.
I can either pay directly, or make a donation on your behalf to a charity or non-profit of your choice.
$50 Bounties
(Unclaimed) Existence (or not) of Soo Machine & Auto licence plate frames
Criteria: Proof of the existence of “Soo Machine & Auto” license plate frames (including what they looked like). This excludes any frames from the Hollingsworth Auto and later eras.
OR
Criteria: Reasonable proof that “Soo Machine & Auto” license plate frames never existed. Such as a relative who worked at Soo Machine in the 60’s before the name was changed to Hollingsworth Auto.
I think the best bet is to locate anyone who has a bunch of old car memorabilia or license plate frames in Sault Ste. Marie. I’m trying to track one down for the car that has been in our family since ‘63, or have one recreated if they ever existed.
$25 Bounties
(Unclaimed) Robert A. Morrison's middle name
Criteria: What is Robert A. Morrison’s middle name? I am looking for documentation providing Robert’s middle name. Any documentation should reasonably match known records such as his birth, residences, or known family members.
I’ve done some digging on FamilySearch and attached a few records to Robert’s FamilySearch page to help with future discovery by others. (The website does require an account, but it’s free to use).
It’s possible that Robert A. Morrison was actually adopted by Charles and Sarah Morrison, as he doesn’t show up in the household in the Morrison 1881, and I can’t even being to piece together what happened to the Morrison family by 1891 as they’re all seamingly apart by then. Charles or Sarah show up on any birth records as parents for someone named Robert. By 1901, Robert had seemingly immigrated to the US (1899/1900). So it’s possible that Robert was a relative or close neighbor friend that could have had a different name when he born. I was unable to find any records for a Robert born on October 14, 1880, but that doesn’t mean I searched all of the correct record collections. My theory is that Robert was adopted by the Morrison family between 1891-1899 before he moved away. Which is why Robert later lists Charles and Sarah as his parents on his marriage certificate.
This might make tracking down his original birth records a bit trickier since we don’t necessarily know his birth parents for certain. We’d probably want to start looking for any Robert born in Canada on October 14, 1880 and then check if there are records of his birth parents passing away before 1899.
All documents and newspaper articles that I’ve found for Robert Morrison only list his middle initial as “A”. I’ve tried searching for his birth record in Canada, but I’ve had no luck.
Good resources include newspaper obituaries, death certificates, or cemetery records.
(Unclaimed) Robert A. Morrison's death record/date
Criteria: When did Robert A. Morrison pass away? I am looking for documentation providing Robert’s date of death. Any documentation should reasonably match known records such as his birth, residences, history, or known family members.
I’ve done some digging on FamilySearch and attached a few records to Robert’s FamilySearch page to help with future discovery by others. (The website does require an account, but it’s free to use).
It’s possible that Robert A. Morrison was actually adopted by Charles and Sarah Morrison, as he doesn’t show up in the household in the Morrison 1881, and I can’t even being to piece together what happened to the Morrison family by 1891 as they’re all seamingly apart by then. Charles or Sarah show up on any birth records as parents for someone named Robert. By 1901, Robert had seemingly immigrated to the US (1899/1900). So it’s possible that Robert was a relative or close neighbor friend that could have had a different name when he born. I was unable to find any records for a Robert born on October 14, 1880, but that doesn’t mean I searched all of the correct record collections. My theory is that Robert was adopted by the Morrison family between 1891-1899 before he moved away. Which is why Robert later lists Charles and Sarah as his parents on his marriage certificate.
It appears that Robert A. Morrison left Sault Ste. Marie after selling his ownership of Soo Machine & Auto in 1921 and divorced Violet during this decade.
The last possible known record I have of Robert Morrison is from an April 29, 1929 article in The Evening News that states, “Robert Morrison of Milwaukee, a former Sault resident who has been spending several days in the city on business returned this evening to his home.” But I don’t think he spent a long time there.
In the 1920 census, Robert and his wife, Violet, are still living together. However, Robert is listed as “married” while Violet is listed as “single”. (Speculating) They may have been in the process of getting a divorce at this time, which is why Robert sold his ownership of Soo Machine and moved away.
By the 1930 census, Violet’s record shows her living with her parents and lists herself as “divorced”.
I believe this 1930’s census record from Douglas, Nebraska, belongs to the same Robert A. Morrison from Soo Machine & Auto. My supporting evidence:
- Name: Robert A. Morrison (he always includes his middle initial on documents)
- In the 1930s census, he is listed as “divorced”; which matches Violet’s census record
- Born between 1877-1881
- Listed as Canadian (Ontario) born
- Immigrated in the year 1900
- WWI veteran (this one helps the most!)
There are only a handful of WWI-drafted men named Robert Morrison who were born in 1879 ± 1 year. Source.
From that large list above, we can eliminate any person whose last name does not begin with the letter ‘A’. Since we know Robert A. Morrison was born in Canada, we can remove any names of natural-born US citizens.
That leaves us with only 4 possible individuals with the name Robert Morrison.
- Robert A. Morrison of Michigan
- Robert Morrison of Philadelphia
- Robert Morrison of Pittsburgh
- Robert Arthur Morrison of Los Angeles
We can elimitate “Robert Morrison of Philadelphia” because the census record lists “Ireland” as his country of birth. I found this in a marriage licence record for a Robert Morrison in Philadelphia with a matching birthday and spouse’s name. Source.
If we make a search in the 1920s US census for Robert Morrison’s born in Canada between 1877 and 1881, we only find 2 remaining individuals that could fit the name. “Robert Morrison of Pittsburgh” never shows up in my census searches (not to be confused with the Robert Morrison in Philadelphia). Source.
- Robert J. Morrison of Michigan (“J” is likely a mishearing of “A” as Robert is still listed as still living with Violet in Sault Ste. Marie on this record)
- Robert A. Morrison of Los Angeles
However, in 1922, the Robert A. Morrison of Los Angeles passed away. Source.
This aligns with the 1930s census search, where only one remaining Robert Morrison seems to match our search criteria. Source.
This means that the only remaining Robert Morrison that fits our search criteria is the Robert A. Morrison in Nebraska from the 1930s and 1940s US Census records.
- 1930s US Census record (this one lists him as a WWI veteran)
- 1940s US Census record
At the age of 63 in the 1940s census record, it lists him as unable to work.
If we try to search for Robert Morrison’s in the 1950s US Census, we no longer find anyone that matches our criteria. Source.
This would indicate that Robert A. Morrison was either been missed, moved out of the US, or likely passed away between 1940 and 1950.
I am looking for an exact date of death as part of this bounty.
Reflections: The Joy of Discovery and the Power of Automation
This journey into the history of Soo Machine & Auto, Hollingsworth Auto, Braun-Mansfield, and F.M. Mansfield has been a rewarding one. Not only have I learned new skills and overcome technical challenges, but I’ve also discovered fascinating stories about the people and places connected to these businesses. It’s a testament to the power of technology to revive forgotten histories and connect us to our past.
If you’re inspired to embark on your own historical data project, remember that the tools and techniques I’ve shared are just the beginning. The key is to approach the process with curiosity, passion, and a willingness to learn. Happy exploring, and may your journey into the past be as enriching as mine has been!